Aryan Mittal
Aryan Mittal
Detecting Disease from Respiratory Audio





Description
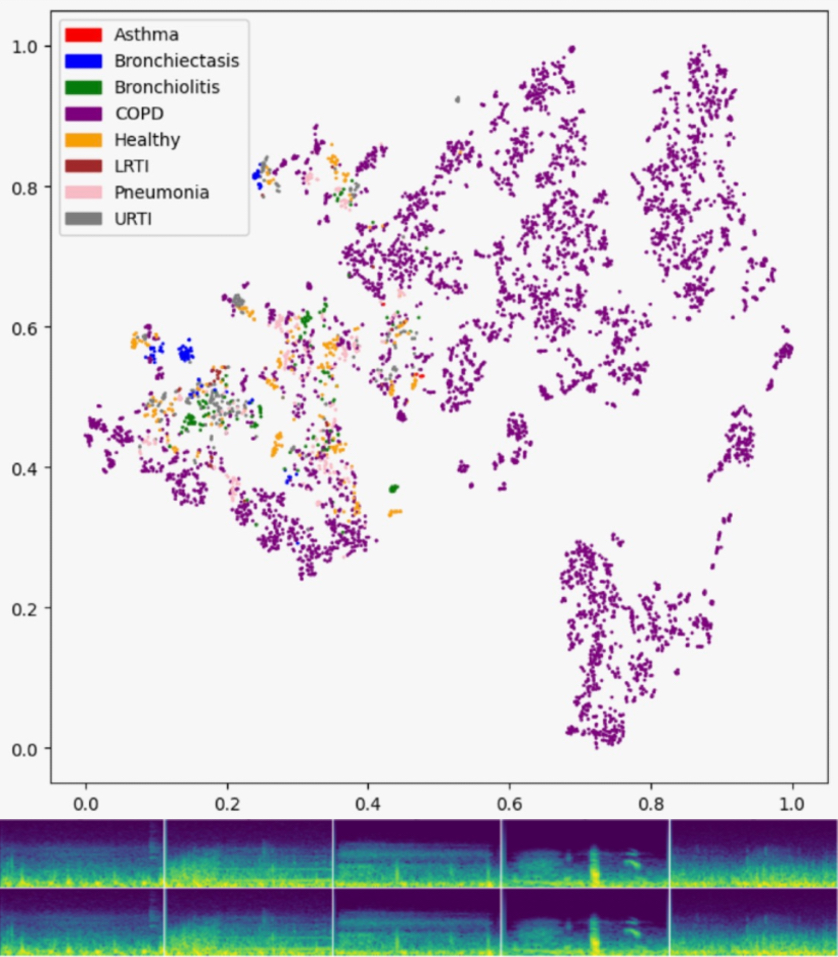
A supervised and unsupervised learning approach to analyzing breathing audio data collected via stethoscope. We achieve a 91.3% accuracy rate in distinguishing between 7 different respiratory conditions using a ResNet-based architecture on audio spectrograms. This was completed as my final project for Georgia Tech’s CS 7641: Machine Learning.
Due to the scarcity of examples in the dataset compared to the number of disease categories, future work on this project will be targeted towards (1) solving the original ICBHI problem of detecting crackles and wheezes in the audio files themselves, (2) making the repo self-contained (e.g., adding a script for data acquisition), and (3) deploying a web app demo for the model. Leading concepts for further research include deep sequential models modified for audio (e.g., Mamba, xLSTM, Degramnet, etc.), intelligent encoding of audio clip metadata (e.g., recording device, auscultation location, patient demographics), and more advanced preprocessing methods, such as those implemented in RespireNet.